Setting a Button to Show a Pop Up and Display a Variable String
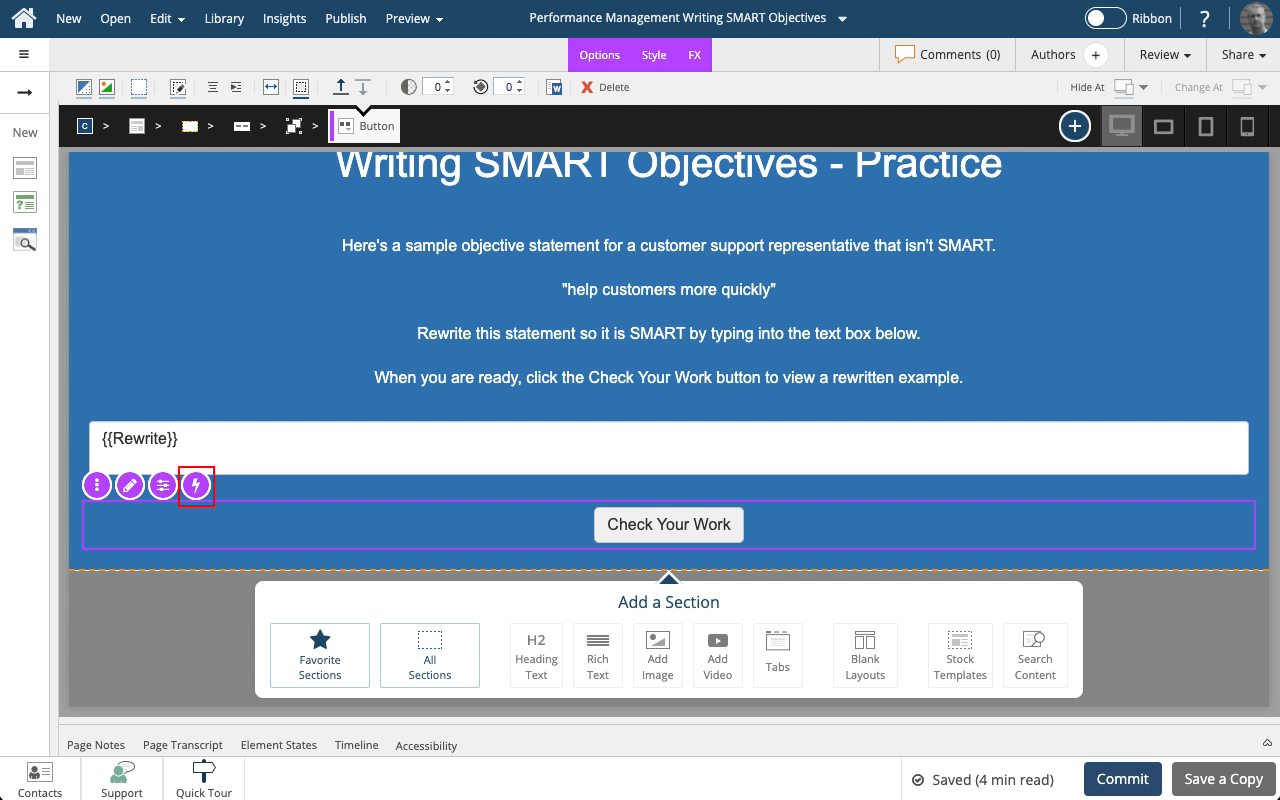
Steps to set a button element to show a Pop Up and display a variable string as feedback.

Steps to set a button element to show a Pop Up and display a variable string as feedback.
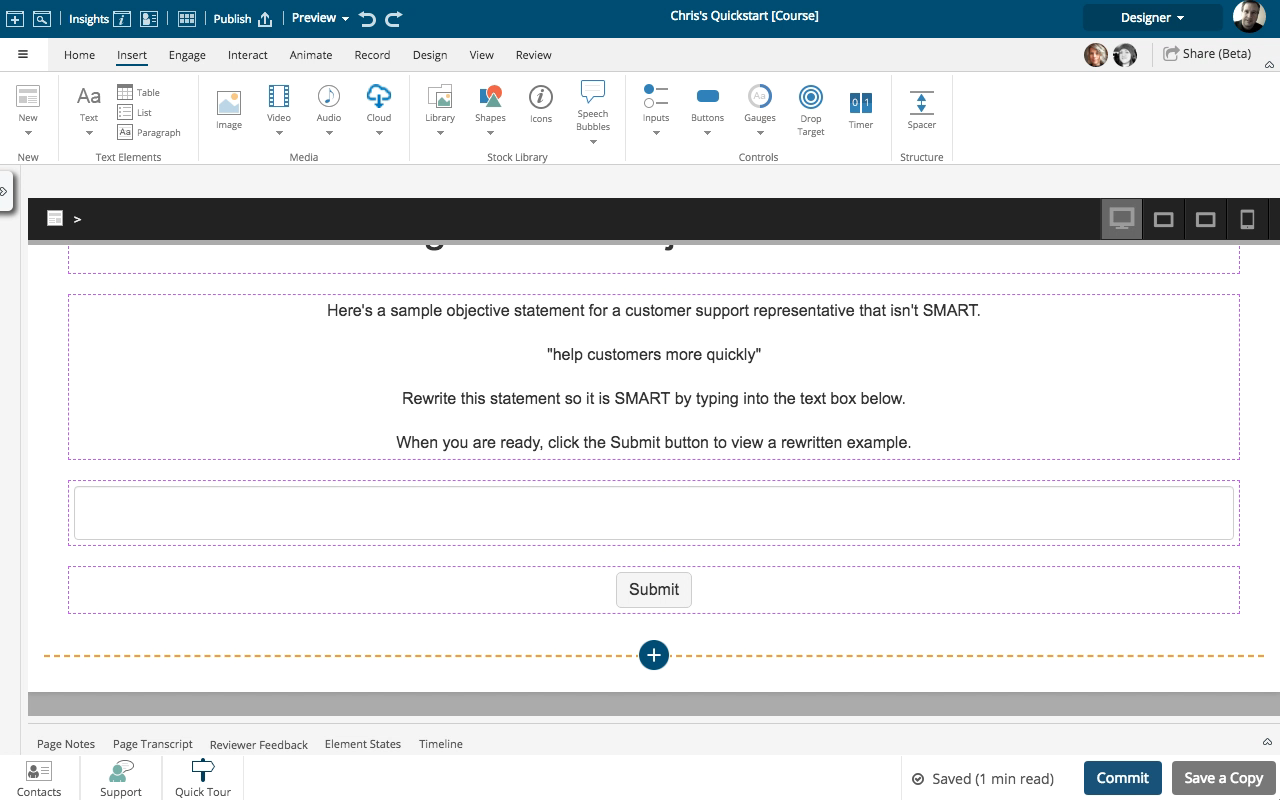
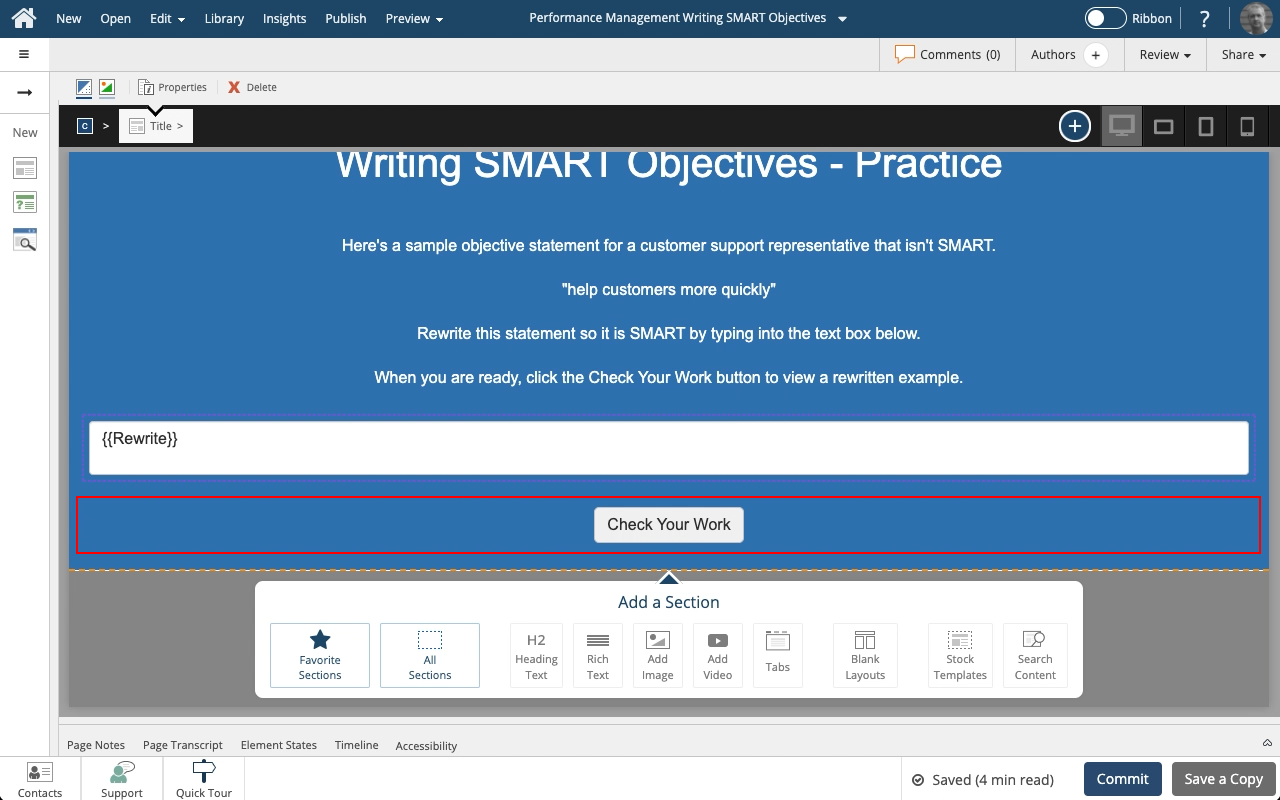
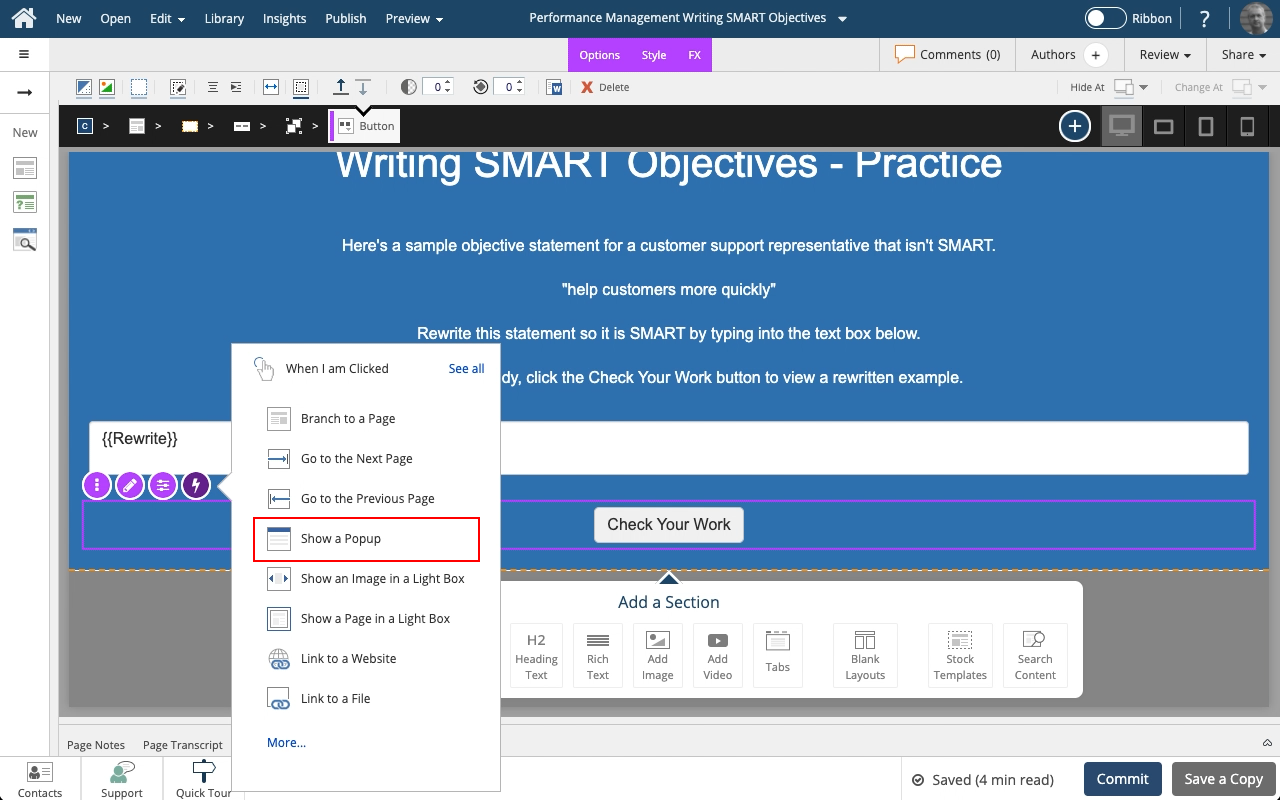
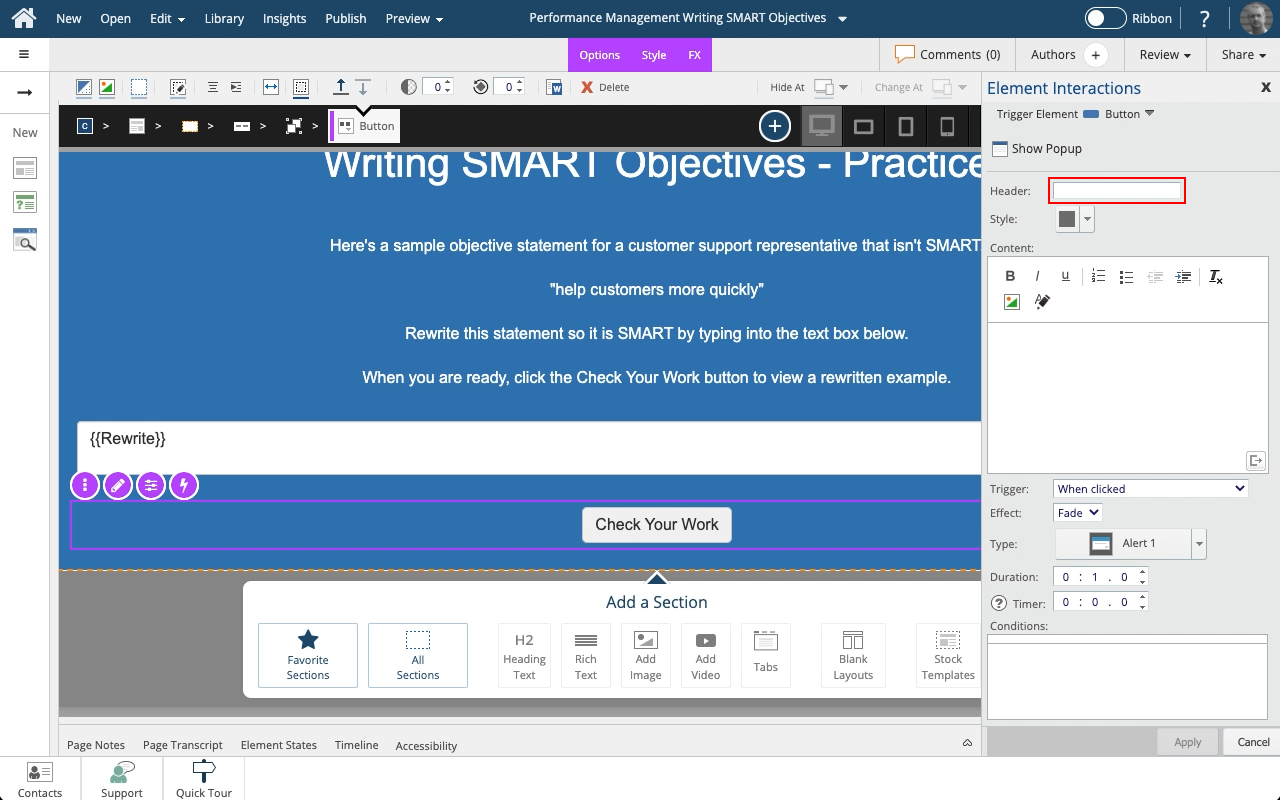
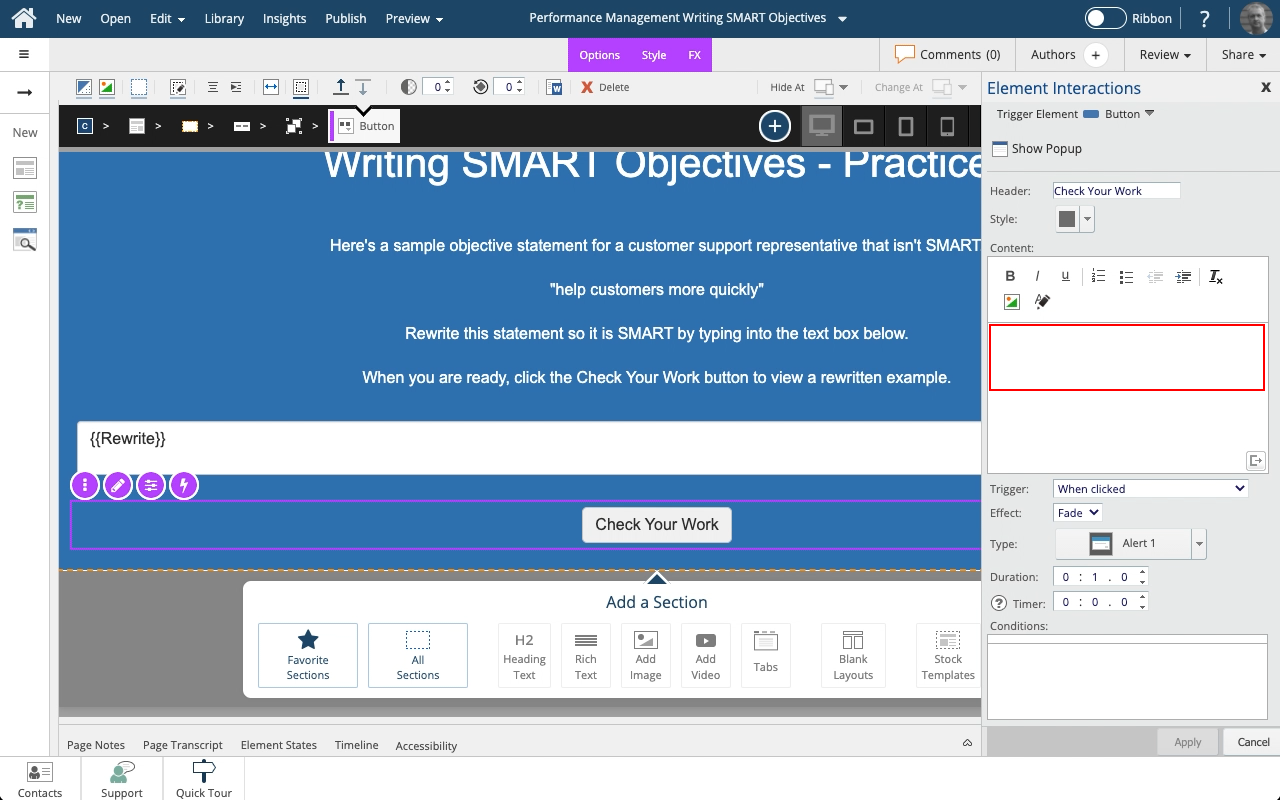
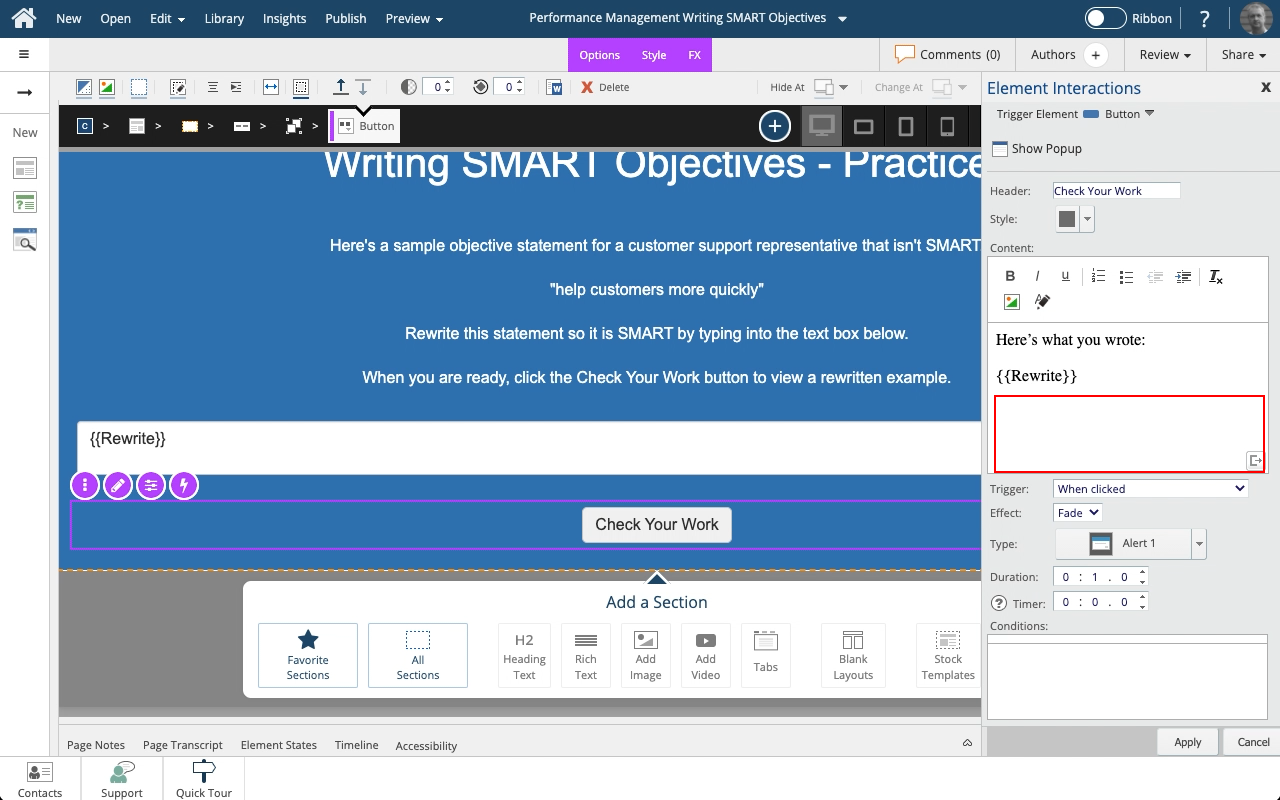
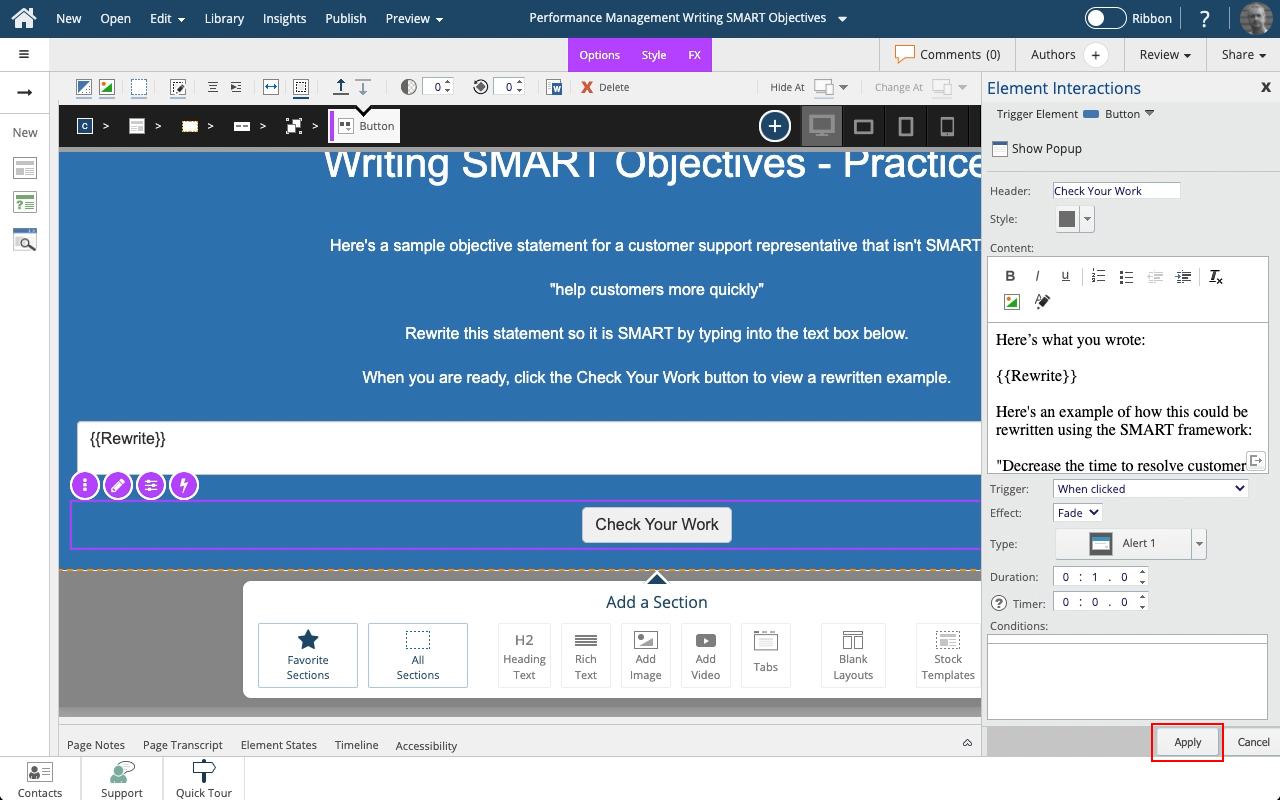
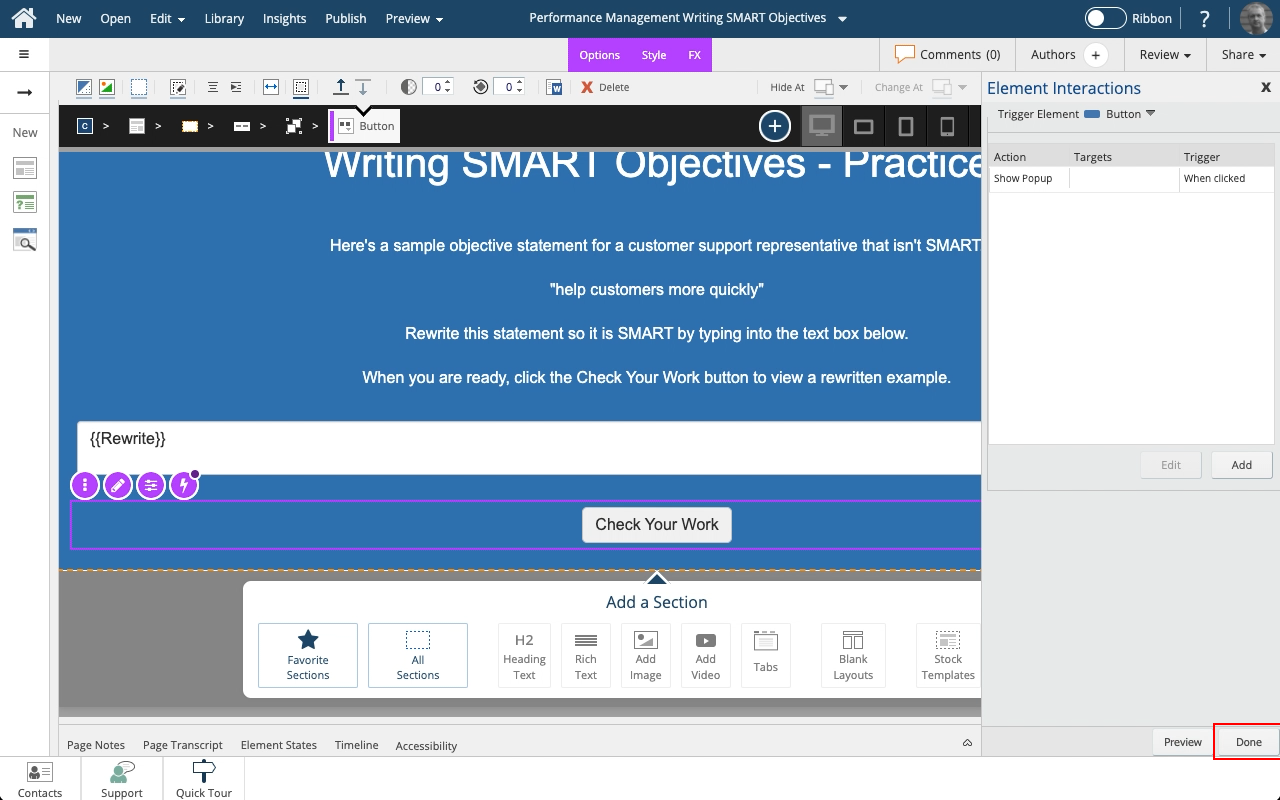
Steps to set a button to show a Pop Up panel as well as include the text string saved to a variable as part of the feedback text on the Pop Up panel.
A Pop Up panel gets shown as a modal window above the main page, which will be shown as grayed-out while the panel is open.
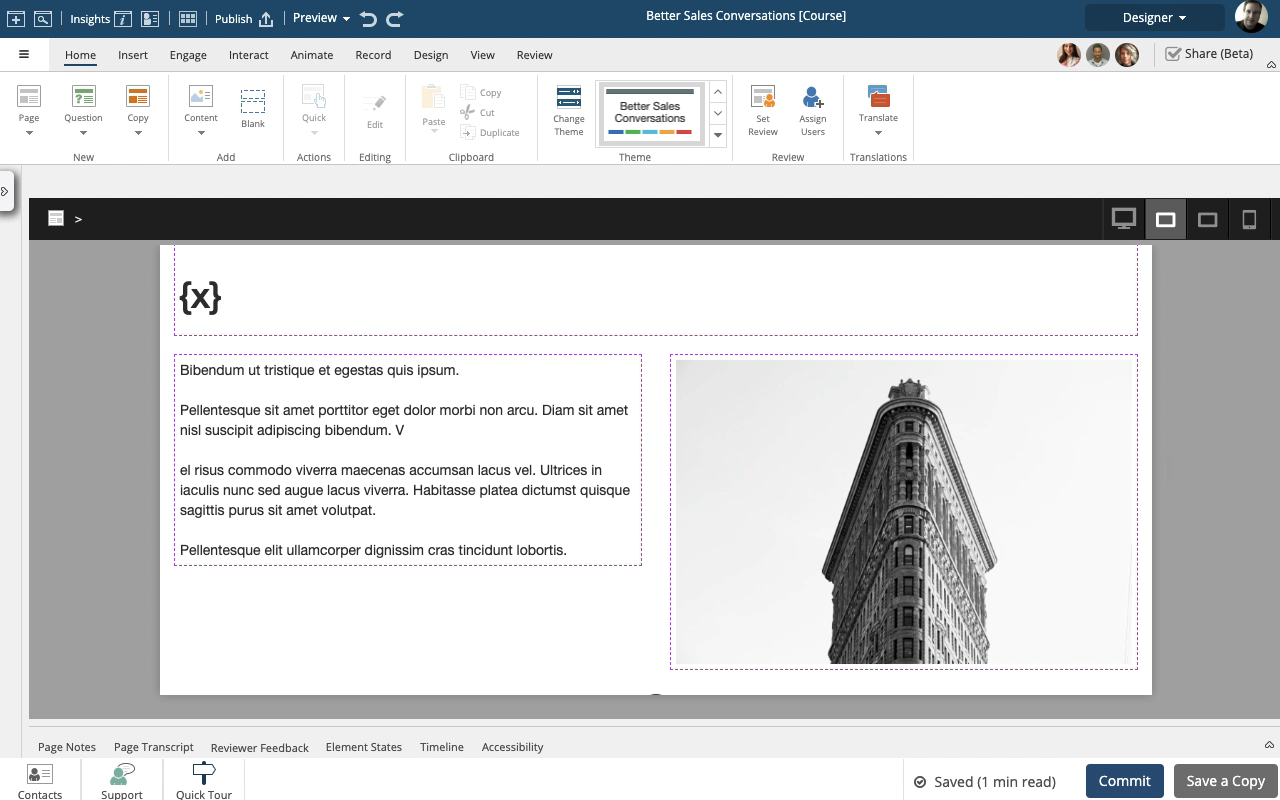
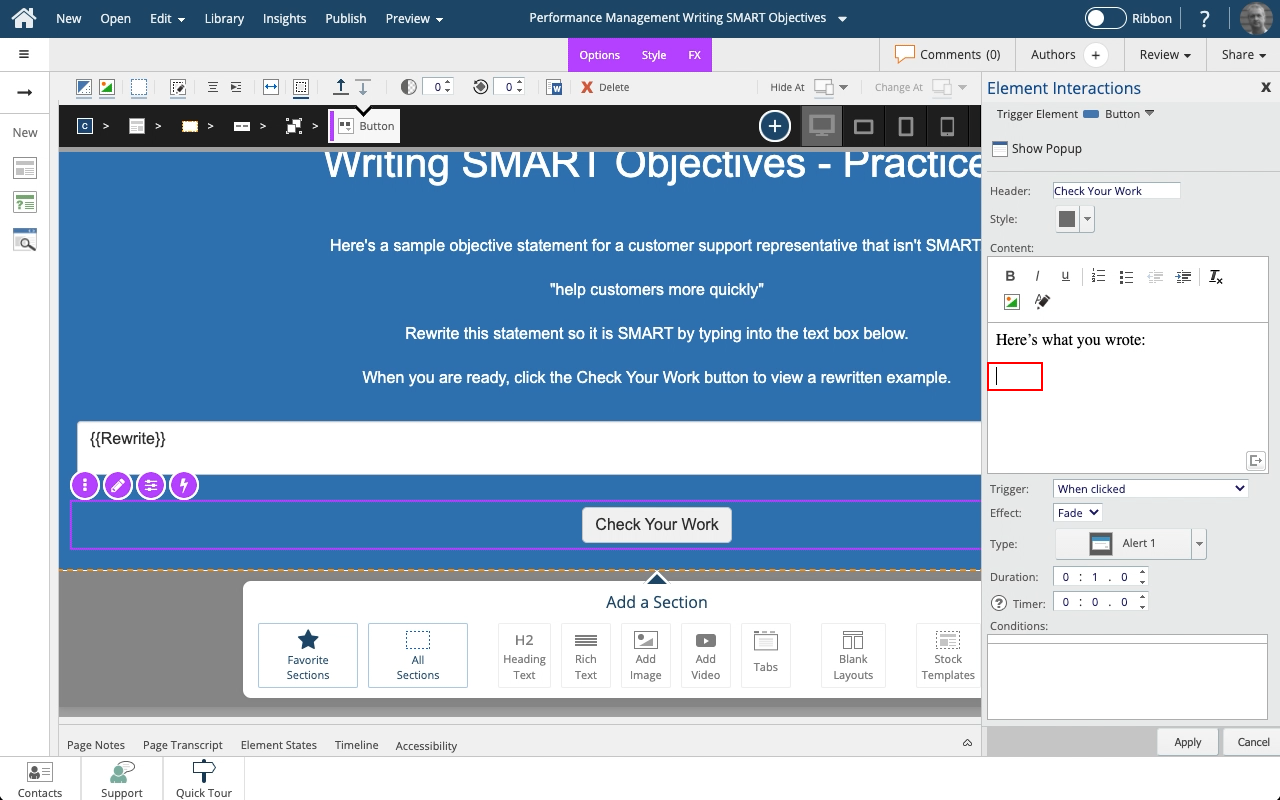
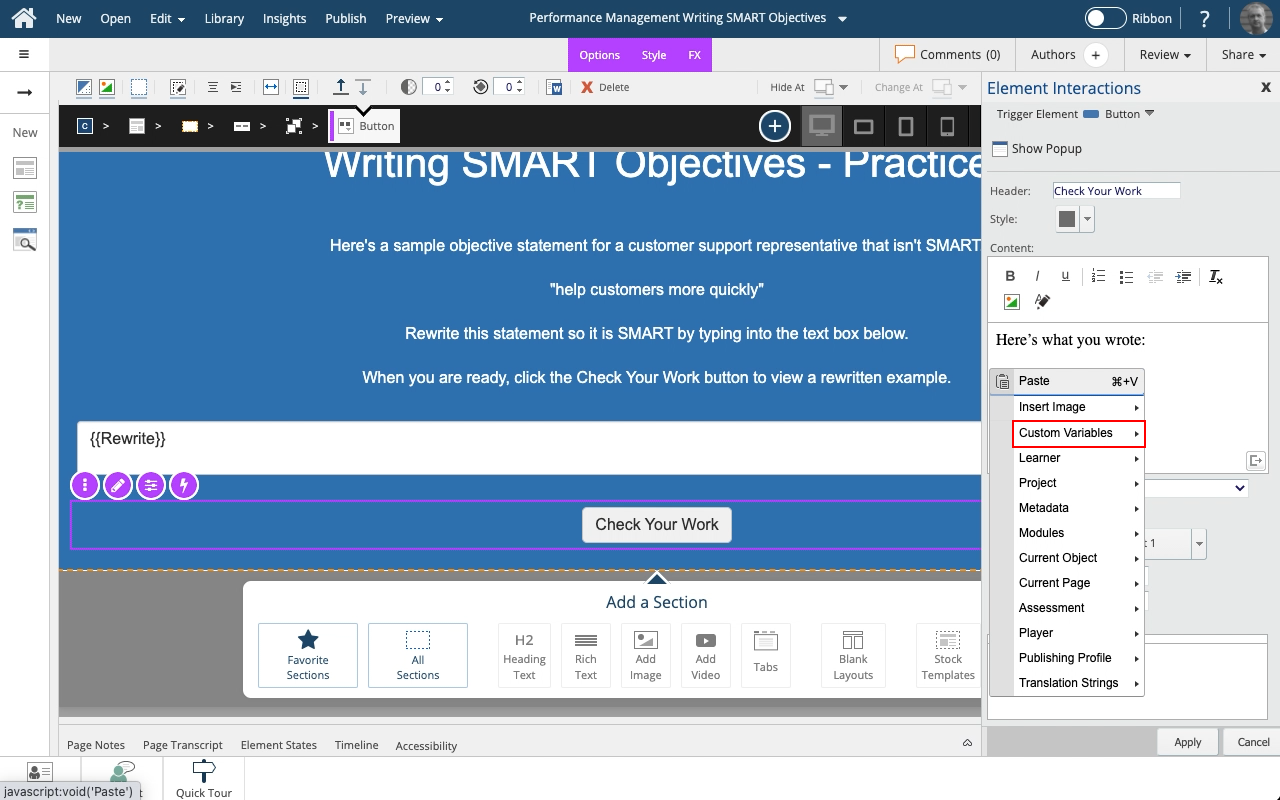
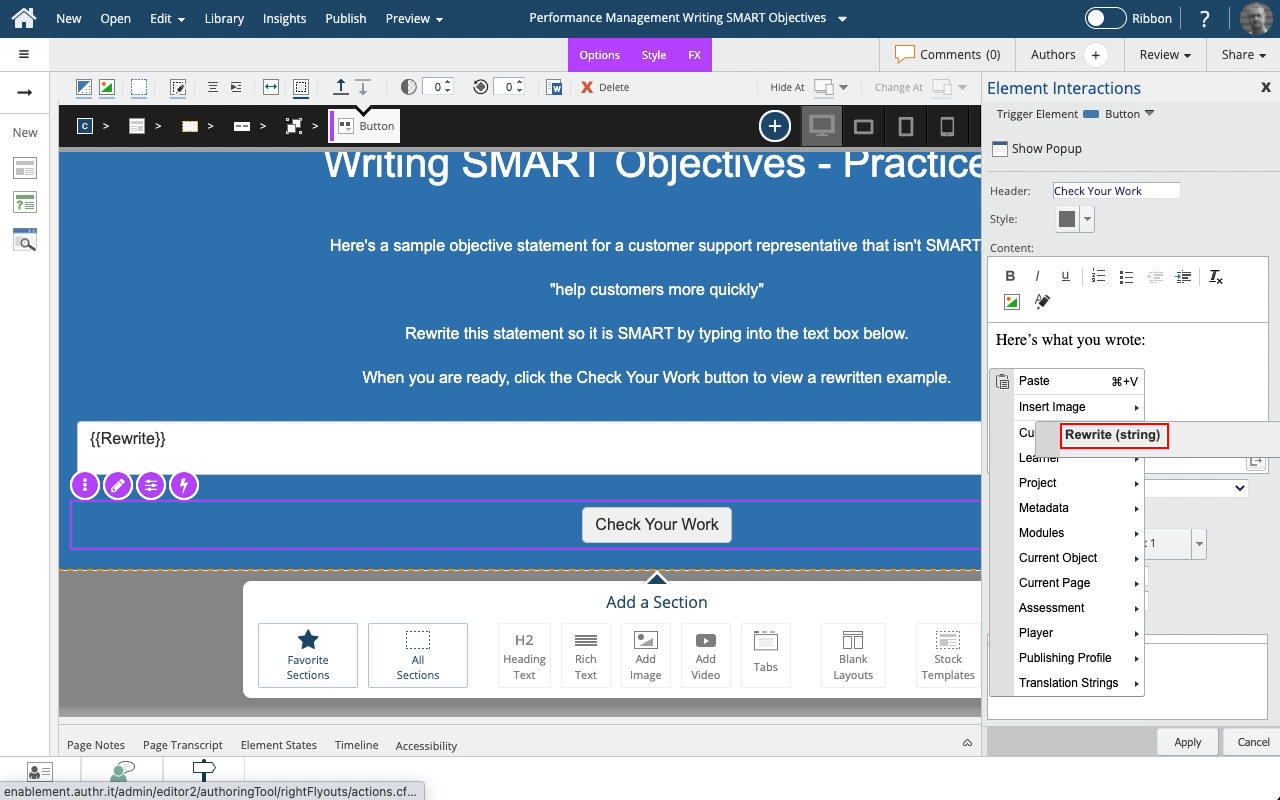
Steps to use the Show Variables setting to display either the default {x} variable placeholder or the full variable string in a text element.
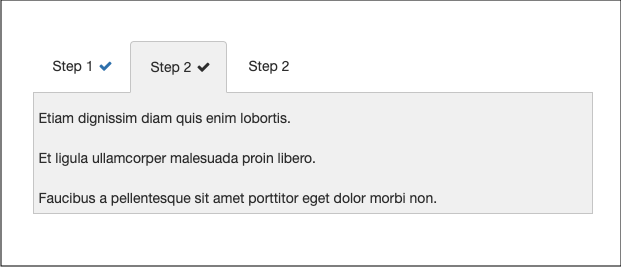
A Publishing Profile setting lets you show learners what they've completed on these interactive Engage components
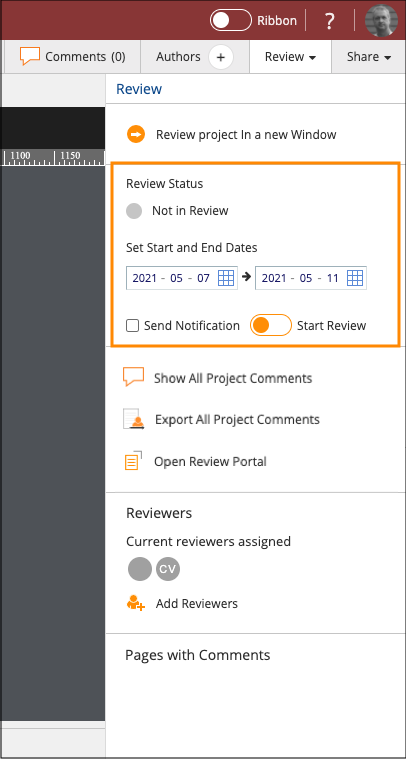
Controlling when your Reviewers can provide Comments on your Project
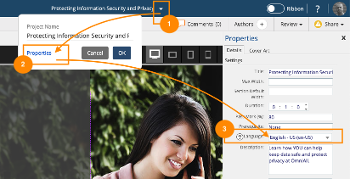
Easily switch the language setting, which controls all dominKnw | ONE provided text
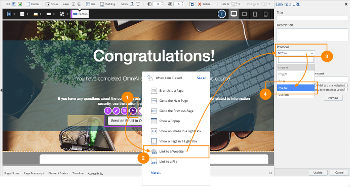
Make it easy for learners to send an email if they have questions or need more information

Allow your users to skip the content and take the test.
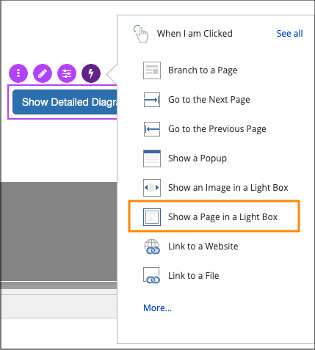
Create unique and engaging learner experiences by showing content in a modal window over your main page
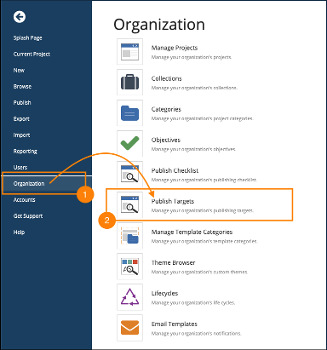
This single-source content feature lets you target multiple audiences or learning contexts in the same Project



Comments ( 0 )
Sign in to join the discussion.